Chap3 JAVA的基本程序设计结构
JAVA语法与C++语法相似,此处仅列出与C语法不同的语法点
- JAVA虚拟机从指定类的main方法开始执行
- main方法必须是静态的
- main方法不直接给操作系统返回“退出代码”,若正常退出,java应用程序返回0。如果希望返回其他代码,需要调用
System.exit方法
- JAVA所有函数都属于某个类的方法
注释
JAVA有三种注释方法
// /*和*/ /**和*/:将注释内容自动生成文档
数据类型
JAVA是一种强类型语言
整型
四种整型类型
int:4字节,约+-20亿 short:2字节,约+-3万 long:8字节,约+-9e19 byte:1字节,-128~127
整型常数表示:
- 默认:十进制
- 后缀
L:长整型
- 前缀
0:八进制
- 前缀
0x:十六进制
- 前缀
0b:二进制
- 常数表示时可以人为的加上下划线
_来使其更容易阅读
如:1_000_000编译器会自动去除下划线
浮点类型
两种浮点类型
float:4字节,6~7位有效数字 double:8字节,15位有效数字 - 通常使用double类型,除非需要快速处理单精度类型数据、需要存储大量单精度类型数据
浮点类型常数表示:
- 默认:double类型
- 后缀
F:float类型
- 后缀
D:double类型
浮点类型的特殊常量
Double.POSITIVE_INFINITY:无穷大 Double.NEGATIVE_INFINITY:无穷小 Double.NaN:“not a number”非数值 - float类型同理
- 判断一个特定值是否为数值
- 不可以使用
if(x == Double.NaN)
- 但可以使用
if(Double.isNaN(x))
浮点类型存在舍入误差
这是因为浮点数值是采用二进制系统表示的,
(2.0-1.1)将得到的是0.899999999999999而不是0.9
所以浮点数值不适用于进制出现舍入误差的金融计算当中,此时可以使用BigDecimal类
字符类型
16字节的UTF16编码格式
JAVA中不建议使用char类型,最好将需要处理的字符串用抽象数据类型表示
boolean类型
- 只有false和true两个值
- 不能和整型相互转换
如if( x=0 ),表达式x=0的值为整型0
- 在C语言中,该语句符合语法
- 但在JAVA中,该语句不符合语法,因为条件表达式要求是boolean类型,而boolean类型和整型不能相互转换
变量
声明
- 可以使用除了“+”、空格等以外的任何unicode字符(包括中文)
- 变量名长度没有限制
- 一次可以声明多个变量,但不建议这样做,每行声明一个变量并给出相应的注释能提高程序的可读性
- 变量声明应尽可能靠近第一次使用的地方,而不一定都在函数开头
- JAVA不区分“定义”和“声明”
- 局部变量不会自动初始化为null
常量
- 定义借助
final关键字,如final double pi=3.14
- 常量只能被赋值一次
- “const”也是JAVA的保留字,但并不使用
运算符
一般运算
- 整数除以0会引发异常,浮点数除以0会得到无穷大或NaN
- 支持
+=、++、A?B:C、位运算符
- 对两个boolean值进行
&或|运算,两边的表达式都要经过计算
但若进行&&或||运算,则采取“短路”原则
- C和C++对于
>>运算采取“符号拓展”还是高位补0是不确定的
但JAVA规范为“符号拓展”,即可用于任意整型
- JAVA不支持幂运算符
^
- JAVA不支持逗号运算符,但在for语句中可以用for分隔表达式列表
数学函数与常量
包含于数学类Math中
- 幂运算:
Math.pow(x,a)
- 其他:
Math.sin()
Math.cos()
Math.tan()
Math.atan()
Math.exp()
Math.log()
Math.log10()
等等
- 数学常量
Math.PI
Math.E
等等
Math类的方法都采用计算机浮点单元中的例程以获得最快的性能
如果需要确保在所有平台上得到相同的结果,可以使用StrictMath类
类型转换
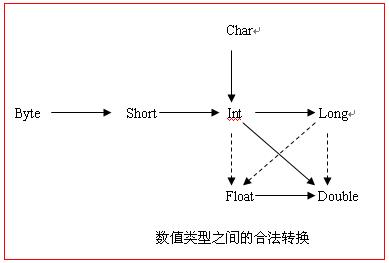
虚线表示转换过程中会损失精度
运算过程中会自动将操作数往“高级别”的类型转换
“级别”顺序:double,float,long,int,“others”
强类型转换
同C语言
- 浮点数转换为整型
- 直接使用
(int)等将自动截断小数部分
- 如果需要进行舍入运算,应借助
Math.round()方法
- 如果尝试将一种类型强制转换为超出范围的另一种类型,其数值将会被截断
- 一般不要将boolean类型强制转换为其他类型,也不要将其他类型强制转换为boolean类型
如果非要这么做,可以借助三元运算符b?1:0
优先级和结合性

与C语言几乎一致,除了少量的特性增减
大致顺序如下:
- 初等运算符、方法调用
- 一元运算符、new
- 算术运算符(先乘除,后加减)
- 位“移”运算符
- 关系运算符(但
==和!=优先级较低)、instanceof
- 位“与”
- 位“异”
- 位“或”
- 逻辑运算符(除了
!,且&&优先级较高)
- 条件运算符
- 赋值运算符
枚举类型
enum Size { SMALL, MEDIUM, LARGE, EXTRA_LARGE };
Size s = Size.MEDIUM;
此时的Size类型变量只能存储这个类型枚举出来的某个值,或是null
字符串
没有内置的字符串类型,但有预定义的String类
双引号扩起来的字符串都是String类的一个实例
java字符串都是Unicode字符序列
子串
String类的substring方法可以提取从较长的字符串中提取出一个子串
String greeting = "Hello";
String s = greeting.substring(0, 3);
注意:这里提取的是0-2的字符,即大于等于0,小于3
拼接
字符串可以用加号+进行拼接
如果字符串跟一个非字符串数值进行拼接,后者将会转换为一个字符串(任何java对象都可以转换成字符串)
不可变字符串
String类对象是不可变字符串,即字符串内容不可以改变
倘若要改变字符串内容,可以借助子串和拼接
如:将greeting变量的内容从“Hello”改为“Help!”
greeting = greeting.substring(0, 3) + "p!";
优点:编译器可以让字符串共享,而通常情况下,共享的使用频率远高于提取、拼接字符串
共享:想象各种字符串存放在公共的存储池,变量指向存储池中相应的位置;复制字符串变量时,原始字符串和复制的字符串共享相同的字符
但有时侯需要用到构建字符串StringBuilder类
另外,当String类的实例指向另一个字符串(重新赋值)时,原始字符串会被垃圾回收机制自动回收
检测字符串是否相等
使用equals方法检测两个字符串是否相等
s.equals(t);
该方法返回一个boolean值
如果需要忽略大小写,可以使用equalsIgnoreCase方法
- C语言中用strcmp函数进行字符串比较
java中也有对应的compareTo方法,但是用equals方法更为直观
- C++语言中直接用
==来判断两个字符串是否相等,
但在JAVA中用==判断的是两个字符串是否在同一位置(有可能共享),一般是没有意义的
空串和null串
空串:长度为0(str.length() == 0),内容为空(str.equals(""))
null串:目前没有任何对象与该变量关联(str == null)
代码点与代码单元
大多数常用的Unicode字符都使用一个代码单元表示,但辅助字符等需要一对代码单元表示
无论是用一个代码单元还是用一对代码单元表示,每个字符就作为一个代码点
length()方法返回的是代码单元的数量 codePointCount(x, y)方法返回代码单元为x至(y-1)的代码点数量
int cpCount = greeting.codePointCount(0, greeting.length())可以获取一个字符串的代码点数量 charAt(i)方法返回位置为i的代码单元
如果想获取位置为i的代码单元,可以这么做
int index = greeting.offsetByCodePoints(0, i);
int cp = greeting.codePointAt(index);
注意:codePointAt()方法的参数为代码单元的索引,而不是代码点的
常用字符串方法
char charAt(int index)
int codePointAt(int index)
int offsetByCodePoints(int startIndex, int cpCount)
int compareTo(String other)
boolean endsWith(String suffix)
boolean equals(Object other)
boolean equalsIngoreCase(String other)
int indexOf(String str [, int fromIndex])
int indexOf(int cp [, int fromIndex])
int lastIndexOf(String str [, int fromIndex])
int lastIndexOf(int cp [, int fromIndex])
int length()
int codePointCount(int startIndex, int endIndex)
String replace(CharSequence oldString, CharSequence newString)
boolean startWith(String prefix)
String substring(int beginIndex [, int endIndex])
String toLowerCase()
String toUpperCase()
String trim()
注意:java一般使用的是不可变字符串,因此上述方法都是返回新串,而不是进行原地操作
构建字符串
有时候需要用较短字符串构建长字符串(如按键、文件中的单词等)
采用String类来拼接字符串每次都产生新串,耗时费空间
此时可以使用StringBuilder类
使用方法
- 构建一个空的字符串构建器
StringBuilder builder = new StringBuilder();
- 不断添加子串或字符
builder.append(ch);
builder.append(str);
- 将builder下的字符串和字符构建成长字符串并返回
String completedString = builder.toString();
StringBuilder类的常用方法
StringBuilder()
int length()
StringBuilder append(String str)
StringBuilder append(char c)
StringBuilder appendCodePoint(int cp)
void setCharAt(int i, char c)
StringBuilder insert(int offset, String str)
StringBuilder insert(int offset, char c)
StringBuilder delect(int startIndex, int endIndex)
String toString()
注意:上述返回StringBuilder的方法,都是返回this
输入输出
输入
相关方法
Scanner(InputStream in)
String nextLine()
String next()
int nextInt()
double nextDouble()
boolean hasNext()
boolean hasNextInt()
boolean hasNextDouble()
static Console console()
static char[] readPassword(String prompt, Object...args)
static String readLine(String prompt, Object...args)
常见用法
import java.util.*;
Scanner in = new Scanner(System.in);
System.out.print("What is your name?");
String name = in.nextLine();
格式化输出
Java沿用了C语言库函数中的printf,此处只列出不同之处
转换符
%d、%x、%o、%f、%e、%g、%s、%c、%%
%b:布尔
%h:散列码
%tx:日期时间,此处x为额外的参数
%n:行分隔符
%a:十六进制浮点数
字符串输出
System.out.print()
System.out.println()输出一行(自动换行)
标志
+、空格、0、-、,
(:将负数括在括号内
,:添加分组分隔符,如3,333,333
#:对于f格式,添加小数点;对于x或0格式,添加0x或0
$:给定被格式化的参数索引,如%1$d, %1$x表示以十进制和十六进制打印第一个参数,注意参数索引是从1开始,而不是0
<:沿用上一个参数的值,如%d%<x表示以十进制和十六进制打印同一个参数
格式化后存储字符串(而不直接输出)
String.format()方法
日期时间参数(即%tx中的x)
%tc:完整的日期和时间,如Mon Feb 09 18:05:19 PST 2004
%tF:ISO8601日期,如2004-02-09
%tD:美国格式的日期,如02/09/2004
%tT:24小时时间,如18:09:19
%tr:12小时时间,如06:09:19pm
%tR:24小时时间(没有秒),如18:09
%tY:年份,如:2004
%tB:月份的完整拼写,如February
%tb:月份的缩写,如Feb
%tm:月份的数字,如02
%td:日的数字,如09
%tA:星期几的完整拼写,如Monday
%ta:星期几的缩写,如Mon
%tH:24小时数字,如18
%tI:12小时数字,如06
%tM:分钟的数字,如05
%tS:秒钟的数字,如19
%tL:三位毫秒数字,如047
%tN:九位毫秒数字,如047000000
%tP:上下午标志(大写),如PM
%tp:上下午标志(小写),如pm
%tZ:时区,如PST
其他:%ty、%tC、%te、%tj、%tk、%tl、%tz、%ts、%tQ
使用方法:
System.out.printf( "%1$s %2$tB %2$te %2$tY", "Due date", new Date() );
或System.out.printf( "%s %tB %<te %<tY", "Due date", new Date() );
文件输入输出
文件输出
Scanner in = new Scanner(Paths.get("myfile.txt"));
如果用一个不存在的文件构造一个Scanner,则会发生异常
文件输入
PrintWriter out = new PrintWriter("myfile.txt");
out.print(".....");
out.println("......");
out.printf(".....", ....);
如果用一个不能被创建的文件名构造PrintWriter,则会发生异常
文件路径
可以用绝对路径,也可以使用相对路径
如果是在控制台调用java,则以控制台的当前路径为基准;
如果是在集成环境调用java,则以IDE设定为基准;
可以通过String dir = System.getProperty("user.dir");来获取当前的路径
流程控制
与C语言基本一致,只有以下少数区别
嵌套的语句块内不能重定义外层语句块的同名变量
public static void main(String[] args)
{
int n;
...
{
int k;
int n;
}
}
没有goto语句,但是break语句可以带标签
可以利用带标签的break语句跳出多层循环
但“goto”仍作为Java的保留字
在循环中检测两个浮点数是否相等需要特别小心
如for(double x=0; x!=10; x+=0.1) ....有可能永远不会跳出循环
因为浮点数存在舍入误差,x可能从9.99999999999998跳到10.09999999999998
switch语句中的case
大数值
java.math包中包含了BigInteger类和BigDecimal类,
分别用来支持任意精度的整型和浮点型计算
相关方法
BigInteger add(BigInteger other)
BigInteger subtract(BigInteger other)
BigInteger multiply(BigInteger other)
BigInteger divide(BigInteger other)
BigInteger mod(BigInteger other)
int compareTo(BigInteger other)
static BigInteger valueOf(long x)
BigDecimal divide(BigDecimal other, RoundingMode mode)
static BigDecimal valueOf(long x [, int scale])
使用示例(以BigInteger为例)
BigInteger a = BigInteger.valueOf(100);
BigInteger b = BigInteger.valueOf(10);
BgiInteger c;
c = a.add(b);
c = a.subtract(b);
c = a.multiply(b);
c = a.divide(b);
c = a.mod(b);
if( a.compareTo(b) ) ;
数组
声明
int[] a;
int[] a = new int[100];
int[] a = new int[n];
数字数组:所有元素初始化为0
boolean数组:所有元素初始化为false
对象数组(如字符串数组):所有元素初始化为null
获取数组长度:a.length,这是数组的一个属性,而不是方法,不需要加括号
for each循环
for( int element : a )
.... ;
将可迭代对象(实现Iterable接口的对象)的每个程序暂存于变量element
如果需要打印整个数组,可以这样使用System.out.println( Arrays.toString(a) ),将得到诸如[2,3,5,7,11,13]的输出
数组初始化、匿名数组
int[] smallPrimes = {2, 3, 5, 7, 11, 13};
smallPrimes = new int[] {17, 19, 23, 29, 31, 37};
Java还允许长度为0的数组,如new elementType[0]
注意:数组长度为0与null不同
数组拷贝
浅复制(共享)
int[] luckyNumbers = smallPrimes;
深复制
借助Arrays.copyOf(Arrays x, int length)方法,拷贝x数组的length个元素生成新数组并返回
int[] copiedLuckyNumbers = Arrays.copyOf(smallPrimes, smallPrimes.length);
也可以巧妙地用来增长数组:
luckyNumbers = Arrays.copyOf(luckyNumbers, 2 * luckyNumbers.length);
命令行参数
public static void main(String[] args)中的args即为命令行参数
与C不同的是,命令行参数不包含文件名
即对于命令java Message -h world,程序获取的第一个参数,即args[0]是-h而不是java或Message
数组排序
Arrays.sort(a):原地操作,用优化的快速排序法对a数组进行排序
Math.random()方法可以返回一个0-1但不包含1的随机浮点数(乘以n后可以获得0-(n-1)的随机整数)
相关方法
static String toSrting(type[] a)
static type copyOf(type[] a, int length)
static type copyOfRange(type[] a, int start, int end)
static void sort(type[] a)
static int binarySearch(type[] a [, int start, int end], type v)
static void fill(type[] a, type v)
static boolean equals(type[] a, type[] b)
多维数组
double[][] balances;
double[][] balances = new double[10][10];
int[][] magicSquare =
{
{16, 3, 2, 13},
{5, 10, 11, 8},
{9, 6, 7, 12},
{4, 15, 14, 1}
};
System.out.println( Array.deepToString(a) ); //快速打印整个多维数组
不规则数组
Java的多维数组实际上是“数组的数组”,可以方便地构造不规则数组
//例如构造一个三角形的不规则数组
int[][] odds = new int[10][];
for(int n = 0; n < 10; n++)
odds[n] = new int[n+1];
