《Java核心技术》笔记
- 省略chap1和chap2
- chap3 Java的基本程序设计结构
- chap4 对象与类
- chap5 继承
《Java核心技术》笔记
使用ipython notebook学习python
模仿教材敲代码并用注释或markdown在旁写下注解
指针和数组是C语言中常用的类型(数据结构)
《C Programming Language》一书中提到,指针访问比数组访问效率高一些,这是真的吗?
本着一个求知(ba gua)的心,我决定一探究竟=。=
数组和指针的关系、区别是什么?
a[6]和6[a]是等价的6[a]是成立的,但是为了程序的可读性,尽量不要刻意这么用 a[2][2]的形式 a[2,2]的形式 显然,C语言所说的“多维数组”,本质上是“数组的数组”
简单来说,C语言以“行主序”的规则布局内存,也就是说“最右边的下标先变化”
以二维数组为例,a[2][4]的内存布局如下:a[0][0], a[0][1], a[0][2], a[0][3], a[1][0], a[1][1], a[1][2], a[1][3]
锯齿状数组:某一维或某几维长短不一的数组
以二维数组为例,char a[5][50]
我可以在a[0]保存一个很长的字符串,在a[1]保存一个很短的字符串,但是这样做就浪费了许多的空间
这时候,我们就可以创建一个锯齿状数组来节约空间
char my_string1[] = "aaaaaaaaaaaaaaaaa";
char my_string2[] = "a";
char *my_strings[5] = { my_string1, my_string2 };
char a[3];和char b[4];不是同种类型虽然元素都是字符,而且都能通过char *指针访问,但它们的确是属于不同的类型
用二维数组来展示更加明显,假定char c[1][2];、char d[3][4];
那么前者只能由指针char (*p)[2];来访问
后者只能由指针char (*q)[4];来访问
两者显然是不同的
char *p = "abc";和char a[] = "abc"前者的”abc”保存在常量区中,不可改变
后者的”abc”保存在栈中,是可变的
如果试图改变前者的元素,如p[1] = 'd';,编译能够通过,但运行时会导致程序异常(试图修改常量区内容)char *p = "abc";这种写法存在着弊病,C++尝试否定这种写法,但这种写法过于普遍,最后为了兼容C而只好接受
更好的写法是认为的加上常量限定符,即const char *p = "abc";,来显式说明p指向的是一个常量
这样,当尝试去修改p所指向的值时,编译器就会报错
无论函数的形参是char a[]还是char *a
a都是一个可变的指针变量,而不会作为一个常量
另外,假定有如下定义:
void main(){
int a[6];
example(a);
}
void example( int a[] ){
/*empty*/
}
sizeof( a )得到的是数组的空间大小(而非长度)sizeof( b )得到的是一个指针的空间大小(而不能取得数组的大小)
所以,无法通过sizeof运算符在函数内部获取到“传入”的数组的大小
另外,为了直观,应尽量使用形参char *a
《C专家编程》指出,
“使用现代的产品质量优化的编译器,一维数组和指针引用所产生的代码并不具有显著差别”
这里以char a[] = "abcd";和char *p = a;为例
比较a[3]和p[3]的区别
(假设a数组的首地址为123,p的地址为789)
a[3] 123 + 3 * 1得到a的第四个元素地址为126126处提取一个字节的字符 p[3] 789处提取四个字节的地址,即a数组的首地址123 123 + 3 * 1得到a的第四个元素地址为126126处提取一个字节的字符 可以看到,指针访问比数组访问多了一个步骤,从这一点看,通过下标的方式,数组访问的效率反而稍高一些
这里以char a[] = "abcd";和char *p = a;为例
通过两种方式来遍历数组中的所有元素
(假设a数组的首地址为123,p的地址为789)
数组访问
for(i=0; i<3; i++){
t = a[i];
}
123 + 0 * 1得到a的第一个元素地址为123123处提取第一个字符’a’ 123 + 1 * 1得到a的第二个元素地址为124124处提取第二个字符’b’ 指针访问
for(i=0; i<3; i++){
t = *p++;
}
789处提取四个字节的地址123123处提取第一个字符’a’p + 1为124 789处提取四个字节的地址124124处提取第一个字符’b’p + 1为125 可以看到,数组访问每次都要计算目标地址,而指针访问只需要直接提取数据
尽管指针需要偏移,但只作加减运算,而数组访问需要进行乘法运算,显然效率低一些
(实际上,现代计算机处理器的乘法运算得到很好的优化,其计算速度已经接近加减运算了,真正的瓶颈在于除法运算)
现代编译器常常会直接把数组转换成对应的指针形式,
在这种编译器下,无论是数组访问还是指针访问都会形成相同的机器指令
书上底层的东西比较多,还有些东西不是很理解,等学习完更多的东西后得回头看看
知识点比较杂,这里只是简单的把自己觉得有用的东西罗列出来
sizeof(int) sizeof(a)和sizeof a\0)val & mask != 0 c = getchar() != EOF msk << 4 + lsb i = 1, 2 if( a == b & c == d )的语句if( a == b && c == d)的执行效果是相同的x = f() + g() * h();,其中f()、g()、h()谁先调用是未定义的(注意f()不一定是在g()和h()之后) gets(line)改为if( fgets(line, sizeof(line), stdin) == NULL ) exit(1); \转义回车来将代码分解为多行\之后不小心加入了空格,将带来难以发现的bug z=y+++x将被解释为z = (y++) + x(但是最好还是用括号显示表示出来) int *p;int &p;更为合理(C++已采纳这种声明形式) int const * grape;:指向的整型只读int * const grape;:指针只读*之后针对指针,接在int之后针对整型 int (*foo[])();,最贴近的是[],即foo是一个数组 union bits32_tag{
int whole;
struct { char c0, c1, c2, c3; } byte;
} value;
typedef和#defineint (*foo[])();的定义“封装”起来typedef int (*A[])();和#define NEW(B) ( (*B[])() ) A x;和NEW(x);等价,均可行 A x, y;和NEW(x, y);不等价,只有前者可行 *.a):编译过程中,所用到的函数会被装入到可执行文件中(即每个程序对函数代码有一份单独的拷贝)*.so):编译过程中,只把用到的库文件名或路径名装入可执行文件,需要时再实时调用(即每个程序对函数代码共用一份拷贝) <setjmp.h> setjmp( jmp_buf j ):保存当前的过程活动记录到j,并返回0 longjmp( jmp_buf j, int i ):跳转到变量j所在的过程活动记录位置,并返回i setjmp / longjmp和{标签} / goto:/usr/ccs/bin)目标代码反汇编工具 /usr/ccs/bin)打印目标文件的符号表 /usr/bin/time)显示程序所使用的实际使用和CPU时间 memcpy( 目的数组, 源数组, 元素个数 )进行快速拷贝errno的值来提示问题原因errno = 0;,函数调用后再检查errno的值int argc, char *argv[]的参数计数器和一个字符串指针数组 a---b为例, ( a-- ) - b a --- b是没有问题的, a - -- b将被解释为a - ( --b ) ++和--之外,/*等也可能产生准二义性问题y=x/*p中/*会被解释为注释起始y = x / * p中/和*会分别被解释为 除法 和 解除引用 =。=最近在看《vim实用技巧》
对一些内容作点简单的记录,方便以后查阅
.命令(一个微型宏)来重复一些简单的操作 A == $a,插入在行末C == c$,替换行末字符并持续插入s == cl,替换当前字符并持续插入S == ^c,替换前一字符并持续插入I == ^i,从行首开始编辑o == A<CR>,在下方插入新行O == ko,在上方插入新行…… {edit}:.重复,u回退 [f|F|t|T]{char}:;重复,,回退 下[/|?]{pattern}<CR>:n重复,N回退 :s/target/replacement:&重复,u回退 qx{changes}q:@x重复,u回退 .范式daw,可以解读为”delete a word”,该命令可重复 {num}<C-a>加法,{num}<C-x>减法set nrformats=关闭进制识别(都作为十进制数) dw+.的重复风格d2w或2dw的次数风格a couple of;可以提高撤销单元的连贯性 c:修改 d:删除y:复制到寄存器 g~:字母大小写反转 gu:字母转换为小写 gU:字母转换为大写 >:增加缩进 <:减小缩进 =:自动缩进!:用外部程序过滤{motion}跨越的行[h|j|k|l]:左下上右 [-|+]:上一行(下一行)的非空白字符0(数字):行首(含空白)^:行首(不含空白),即本行第一个非空白字符 $:行末 gg:文首 G:文末 [f|F|t|T]{char}:右侧(左侧)的第一个char字符[;|,]:下一个(上一个)”f|F|t|T”的char字符:{num}:至第num行 [w|b]:后一个(前一个)或当前单词的头部(尾部)——含符号 [W|B]:后一个(前一个)或当前单词的头部(尾部)——跳过符号(仅字母和数字包括负号)............................ a:即an,表示一个非空白对象 i:即inner,表示一个内含对象g~~、guu、gUU <ESC>来退回普通模式<C-h>:删除前一个字符,相当于退格键 <C-w>:删除前一个单词 <C-u>:删除至行首 <C-[>更加方便 <C-o><C-o>zz迅速把当前行移动到屏幕正中 <C-r>{register}:将register号寄存器的内容粘贴到当前位置<C-r>={expr}<CR>:执行expr运算并且把结果插入到当前位置 <C-v>{code}<C-v>u{code}<C-k>{char1}{char2}:digraphs查看:digraph-table可以获得二合字母集更详细的信息 ga:屏幕下方会显示当前字符的十进制、十六进制、八进制编码信息 R:替换模式,<Tab>会作为一个字符被替换gR:虚拟替换模式,<Tab>会作为多个字符(一般为八个)被逐个替换(直到末尾才替换掉<Tab>)r和gr同理~v:操作字符文本 V:操作行文本 <C-v>:操作块文本 <C-g>gv:重选上次的高亮选区 .命令有时候会出现异常<C-v>不仅可以选中矩形的区域,还可以选中长短不一的块:的Ex命令 /的查找命令 <C-r>=访问表达式寄存器 :{number}....$表示最后一行,%表示当前文件的所有行 :{start},{end}....,执行命令后光标将跳转到end行 v,V,<C-v>选取高亮区:,此时命令行会自动填充成:'<,'>,表示作用在高亮区上 :/{pattern1},/{pattern2}/....:/<html>/,/<\/html>/指定了html内的所有内容(包含<html>和</html>)/有特殊含义,需要用反斜杠\转义 +或-运算:/<html>/+1,/<\/html>/-1则排除了<html>和</html>而只包含了其中间的内容1:第一行 0:虚拟行,位于第一行上方,常用于插入到首行等功能$:最后一行 .:当前行 %:整个文件,相当于:1,$ 'm:包含位置标记m的行 '<和'>:高亮选取的起始和结束行 :t或:co或:copy:{range}t {address}y命令不同,该命令不把文本保存到寄存器 :move或:m:{range}m {address} :{range}normal {commands},常用于多行的处理:{range}normal .:对多行重复同一操作 :{range}normal A;:对多行末尾补上分号 :{range}normal i//:将多行内容注释掉 @: <C-o>进入插入-普通模式时,命令记录会跳转到上一条命令,可以借此进行命令记录的跳转<Tab>自动补全命令<Tab>会正向遍历补全列表的内容 <S-Tab>反向遍历补全列表,S表示<shift>按键 <C-d>显示可用的补全列表 set wildmode=longest,list set wildmenu和set wildmode=full wildmenu为补全导航列表 <C-r><C-w>会复制当前单词到命令行中 :下保持提示符为空按<up>(<C-p>)和<down>(<C-n>) <C-p>``<C-n>和<up>``<down>的区别.vim文件中创建映射项cnoremap <C-p> <Up>cnoremap <C-n> <Down> :help<up>回溯以”help”开头的命令 set history=200 |隔开命令即可 q::打开Ex命令的命令行窗口 q/:打开查找命令的命令行窗口 <C-f>:从命令行模式切换到命令行窗口(起始命令行模式下输入的内容仍然保留下来) !{command} %代表当前文件名 :shell可以打开一个交互式的shell会话(通过exit退出)<C-z>挂起vim所属进程,用fp唤醒挂起的作业jobs命令可以查看当前的作业列表 :read !{cmd}将命令输出读取到当前缓冲区中:write !{cmd}:将当前缓冲区内容作为命令的标准输入 :{range}!{filter}:2,$!sort -t ',' -k 2表示第2行到最后一行之间,以逗号为分隔符的第二字段排序 :{range}d {x}:删除指定内容(并保存到寄存器x中):{range}y {x}:复制指定内容到寄存器x中 :{line}put {x}:在指定行后粘贴寄存器x中的内容 :{range}t {address}:复制指定内容到address处 :{range}m {address}:移动指定内容到address处 :{range}join:连接指定行内容 :{range}normal {commands}:对指定范围执行普通模式命令 :{range}s/{pattern}/{string}/{flag}:替换 :{range}global/{pattern}/{cmd}:对指定范围内匹配pattern的所有行执行cmd命令(Ex) 文件读取后在内存缓冲区中
:ls命令可以列出所有被载入到内存中的缓冲区列表 %:当前窗口中可见的缓冲区 #:轮换文件<C-^>可以在两个文件之间快速轮换 :bn或:bnext :bp或:bprevious :buffer {N}:跳转到指定编号的缓冲区 :buffer {bufname}:跳转到可以被bufname唯一标识的缓冲区(若多个缓冲区具有同一标识,可以通过<Tab>选择) :bufdo {commands}:对所有缓冲区执行Ex命令 创建快速遍历缓冲区列表的键盘映射
nnoremap <silent> [b :bp<CR>
nnoremap <silent> ]b :bn<CR>
nnoremap <silent> [B :bfirst<CR>
nnoremap <silent> ]B :blast<CR>
删除:bd或:bdelect
:bd {N1,N2,N3....}:删除列出的缓冲区
:{N,M} bd:删除连续的缓冲区
对一批文件进行分组,其文件顺序可调整*
:args:查看参数列表[]表明了当前的活动文件 :args {arglist}:填充参数列表:args {file1,file2,....} *:表示0到无穷多个字符,但不包含子目录**:表示0到无穷多个字符,包含子目录 :args \cat .chapters`` +代表缓冲区被修改过,此时切换缓冲区会弹出错误信息,可以用感叹号强制切换,此时列表中被标记为a的为活动缓冲区(active),被标记为h的为隐藏活动区(hidden) :w或:write:写入磁盘 :e或:edit:从磁盘中读入到缓冲区(回滚修改操作) :qa或:qall:关闭所有窗口,放弃所有修改 :wa或:wall:全部写入磁盘 :argdo或:bufdo修改一组缓冲区hidden选项:next,:bnext,cnext等命令无需再加感叹号 <C-w>s:水平切分(同高度),新窗口仍为当前缓冲区 <C-w>v:垂直切分(同宽度),新窗口仍未当前缓冲区 :sp {file}或:split {file}:水平切分,新窗口为file内容 :vsp {file}或:vsplit {file}:垂直切分,新窗口为file内容 <C-w>w:轮换 <C-w>{h|j|k|l}:切换到左(下上右)侧的窗口 :clo或:close或<C-w>c:关闭当前窗口 :on或:only或<C-w>o:关闭其他重口 <C-w>=:使所有窗口等宽、等高 <C-w>_:使当前窗口高度最大化 <C-w>|:使当前窗口宽度最大化 {N}<C-w>_:使当前窗口高度调整为N行 {N}<C-w>|:使当前窗口宽度调整为N列 对窗口进行分组
:lcd {path}:设置工作路径:windo lcd {path} :tabe {file}或tabedit {file}:在新标签页中打开file <C-w>T:将当前窗口移动到一个新标签页 :tabc或:tabclos:关闭当前标签页及其所有窗口 :tabo或:tabonly:关闭其他标签页及其所有窗口 :tabn {N}或:tabnext {N}或{N}gt:切换到N号标签页 :tabn或:tabnext或gt:切换到下一标签页 :tabp或:tabprevious或gT:切换到上一标签页 :tabmove {N}:将当前标签页移动到N号标签页之后 :tabmove 0:表示移动到开头 :tabmove:表示移动到末尾 这是一段《代码之美》中的代码,仅用了三十余行实现了^$.*的功能
代码紧凑、优雅,值得研究推敲
/*
逐个尝试把每个text的字符作为匹配项的开头
通过递归用regexp进行尝试匹配
*/
/*match :在text中查找regexp,匹配的入口*/
int match(char *regexp,char *text)
{
/*如果regexp开头为^,从下一个字符开始匹配,而且只需要匹配一次*/
if(regexp[0] == '^')
return matchhere(regexp+1,text);
do{ /*即使字符串为空也必须检查*/
if (matchhere(regexp,text))
return 1;
}while (*text++!= '\0');
return 0;
}
/*matchhere在text的开头查找regexp*/
int matchhere(char *regexp,char *text)
{
if (regexp[0] == '\0')
return 1;
if (regexp[1] == '*')
return matchstar(regexp[0],regexp+2,text);
if (regexp[0] == '$' && regexp[1]=='\0')
return *text == '\0';
/*如果出现句点'.'则直接跳过regexp和text的当前字符*/
if (*text!='\0' && (regexp[0]=='.' || regexp[0]==*text))
return matchhere(regexp+1,text+1);
return 0;
}
/*matchstar :在text的开头查找C*regexp*/
int matchstar (int c,char *regexp,char *text)
{
/*尝试结束星号*的匹配*/
do { /*通配符*匹配零个或多个实例*/
if (matchhere(regexp,text))
return 1;
}while (*text!='\0' && (*text++ ==c || c== '.'));
/*如果星号前为句点'.',那么可以跳过任意字符*/
return 0;
}
学习网站:
w3cschool-javascript
MDN-javascript
javascript的语法很多都跟C差不多
不同浏览器在功能的实现上有很多不同,但是可以使用javascript API接口来解决兼容性问题
WIN8支持javascript来创建windows8 app
脚本内容必须包含在script标签中
HTML中的head标签或body标签中
外部js文件中不能包含script标签
引用外部js文件:在head或body标签中插入<script src=''></script>
字符串,数值,布尔,数组,对象,null,Undefined
var x=2e-2; var语句,如:var x=0; 也可以指明变量类型,借助new关键词
var carname=new String;
var x= new Number;
var y= new Boolean;
var cars= new Array;
var person= new Object;
var person={firstname:"Bill", lastname:"Gates", id:5566}; var cars=["Audi","BMW","Volvo"]; new_Array()var cars=new Array("Audi","BMW","Volvo");var cars=new Array();
cars[0]="Audi";
cars[1]="BMW";
cars[2]="Volvo";
$和_符号开头,但不建议 重新声明并不影响变量的值
function myFunction(var1,var2)
{
......
}
字符串连接使用加号(+)
字符串与数字相加:数字将转化为字符串
全等运算符(===)表示值和类型都相同
其他算术、逻辑运算符与C完全相同
与C完全相同
包含C的所有循环语句
另外支持for/in循环语句,用于遍历,如:
var person={fname:"John",lname:"Doe",age:25};
for (x in person)
{
txt=txt + person[x];
}
与C相同
与C相同,可用于语句或代码块
continue(带或不带标签)都只能跳出循环
break(不带标签)只能跳出循环和switch语句
break(带标签)能跳出所有代码块
示例:
cars=["BMW","Volvo","Saab","Ford"];
list:
{
document.write(cars[0] + "<br>");
document.write(cars[1] + "<br>");
document.write(cars[2] + "<br>");
break list;
document.write(cars[3] + "<br>");
document.write(cars[4] + "<br>");
document.write(cars[5] + "<br>");
}
当出现问题时,Javascript引擎会停止,并生成一个错误信息
与python的try/except语句类似
try
{
//在这里运行代码
}
catch(err)
{
//在这里处理错误
}
catch括号的err内为一个变量,用于错误对象
并且可以在catch代码块中引用这个变量
throw语句,可以接错误信息
如:throw "empty";
当网页被加载时,浏览器会创建页面的文档对象类型(Document Object Model),该模型被构造为对象的树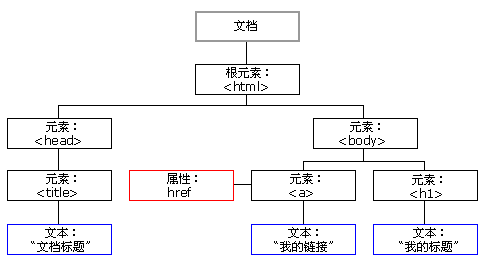
每一个标签都作为对象的一个元素(就像BeautifulSoup的处理方式)
每个元素都包含“属性”和“文本”两部分内容
var x=document.getElementById("intro");
若找到,返回对象;否则返回null
注意大小写
var x=document.getElementById("main");
var y=x.getElementsByTagName("p");
返回的是一个包含多个对象的数组,所以这里的“element”是复数,要注意
由于IE不支持,所以最好不要用
可以用document.write()创建动态的内容,但是绝对不要在文档加载后使用
直接修改对象的.innerHTML属性的值
直接修改对象的.ATTRIBUTE属性的值
这里的ATTRIBUTE为所要修改的“属性名” ,如:x.src="";
直接修改对象的.style.ATTRIBUTE属性的值
这里的ATTRIBUTE为所要修改的“CSS属性名”,如:x.style.color='red';
可以对标签加入事件属性,用来触发javascript语句(一般触发一个函数)
提供的事件属性如下:
onload:进入页面时触发onunload:离开页面时触发onchange:字段变化时触发onmouseover:鼠标移动到元素上时触发 onmouseout:鼠标移出元素时触发 onmousedown:鼠标按住时触发 onmouseup:鼠标按住后释放时触发 onclick:鼠标点击时触发 document.createElement(TAGNAME)document.createTextNode(CONTENT)x.appendChild(NODE)x.removeChild(NODE)示例:
<div id="div1">
<p id="p1">这是一个段落</p>
<p id="p2">这是另一个段落</p>
</div>
<script>
var para=document.createElement("p"); //创建<p>元素
var node=document.createTextNode("这是新段落。"); //创建文本节点
para.appendChild(node); //把文本节点追加到<p>元素上
var element=document.getElementById("div1"); //查找id=div1的标签元素
element.appendChild(para); //把<p>元素追加到id=div1的元素上
</script>
person={firstname:"John",lastname:"Doe",age:50,eyecolor:"blue"};
person=new Object();
person.firstname="Bill";
person.lastname="Gates";
person.age=56;
person.eyecolor="blue";
//这里同时也演示了属性的添加
其实就是一个用来构造对象的函数
示例:(this即为对象自身)
function person(firstname,lastname,age,eyecolor)
{
this.firstname=firstname;
this.lastname=lastname;
this.age=age;
this.eyecolor=eyecolor;
}
myFather=new person("Bill","Gates",56,"blue");
//注意这里的new运算符,而不是直接调用函数
把对象的一个属性绑定到一个内部的一个函数上,这个函数就是该对象的方法
可以通过追加属性添加,也可以在构造器内添加
Javascript时基于prototype的面向对象的语言,并不基于类
也就是说,没有类
所有数值都为8字节,整数精度为15位,小数精度为17位
MAX_VALUEMIN_VALUENEGATIVE_INFINITIVE:负无穷大,溢出时返回该值POSITIVE_INFINITY:正无穷大,溢出时返回该值 NaN:指示值,表明这个数据不是数字isNaN()函数来判断一个变量是否为数字 这些属性是构造函数Number()本身的属性,而不是某个Number对象的属性
所以只能这么用:big = Number.MAX_VALUE;
toString(radix):以radix进制转化为字符串(默认十进制)toLocaleString():以本地的格式转化为字符串(本地格式??) toFixed(num):四舍五入转化为num位小数 toExponential(num):四舍五入转化为num位小数(科学计数法) 这个是对象的属性,而不是构造函数的属性
anchor(ANCHORNAME):创建HTML锚,即将该字符串转换为带属性name="ANCHORNAME"的<a>标签 bold():用粗体显示fontcolor(COLOR):用指定颜色显示 fontsize(SIZE):用指定字体大小显示,SIZE为1-7 indexOf(SEARCHVALUE, FROMINDEX):从FROMINDEX位置(可选)开始搜索SEARCHVALUE子字符串,并返回头部索引,否则返回-1 italics():用斜体显示 link(URL):显示为指向URL的超链接 match(SEARCHVALUE | REGEXP):直接搜索子字符串或通过正则表达式匹配,返回数组replace(REGEXP/SUBSTR, REPLACEMENT):替换,返回结果字符串 search(REGEXP):indexof函数的正则匹配版本 split(SEPARATOR, HOWMANY):以指定的分隔字符串或正则表达式分割字符串,值返回HOWMANY个结果(可选)的数组strike():以删除线显示sub():以下标形式显示 toLowerCase():转换为小写toUpperCase():转换为大写String对象都是不可变的,因此其方法都不做原位操作
var myDate=new Date();
自动使用当前日期时间作为初始值
设置日期:myDate.setFullYear(2008,7,9);
获取时间(从1970/1/1至今的毫秒数):myDate.getTime();
转换为字符串:myDate.toUTCString()
获取本周为第几天(返回一个数字,注意每周第一天是周日):myDate.getDay()
两个Date对象可以直接用比较运算符进行比较
Math对象
Math.EMath.PIMath.round(NUM):四舍五入Math.random():产生0-1的随机数Math.floor(NUM):向下取整示例:(产生0-10的随机数)Math.floor( Math.random() * 11 )
类似python的complievar patt1=new RegExp(PATTERN),PATTERN为匹配模式
可添加第二个参数为"g",表明(global)
test(STRING):检查是否匹配,返回布尔值true和falseexec(SRING):检索匹配项并返回第一个匹配项,否则返回null"g",那么再次执行exec()可以进行下一项的匹配 compile(PATTERN):修改匹配模式,也可以添加修改删除第二个参数 浏览器对象模型(Browser Object Model, BOM)尚无正式标准,但现代浏览器几乎都已经实现了JS交互性方面的相同方法和属性
window对象表示浏览器窗口
任何JS全局对象、函数以及变量都作为window对象的成员
全局变量作为window对象的属性
全局函数作为window对象的方法
如:document.getElementById("header");
实际上是window.document.getElementById("header");
但window一般省略
尺寸即浏览器的视口部分,不包括工具栏和滚动条
有以下三种方法:
window.innerHeightwindow.innerWidth document.documentElement.clientHeightdocument.documentElement.clientWidthdocument.body.clientHeightdocument.body.clientWidth 通常直接使用以下方法来兼容所有浏览器:
var w=window.innerWidth
|| document.documentElement.clientWidth
|| document.body.clientWidth;
var h=window.innerHeight
|| document.documentElement.clientHeight
|| document.body.clientHeight;
window.open():打开新窗口window.close():关闭当前窗口window.moveTo():移动当前窗口window.resizeTo():调整当前窗口尺寸
包含有关用户屏幕的信息,window前缀可以省略
screen.availWidth:可用宽度screen.availHeight:可用高度
用于获得当前页面的信息如URL,也可以把浏览器重定向到新的页面,window前缀可省略
location.hostname:web主机域名location.port:web主机端口location.protocol:所用的web协议(http或https)location.href:当前页面的完整的URLlocation.pathname:当前页面路径和文件名
location.assign(URL):加载新文档
包含浏览器的历史信息,window前缀可以省略
为了保护用户隐私,该对象只允许访问前一个页面和下一个页面(后退和前进)
history.back():加载历史列表的前一个URL(后退)history.forward():加载历史列表的后一个URL(前进)
不包含有关访问者浏览器的信息,window前缀可以省略
appCodeName、appName、appVersion、cookieEnabled、platform、userAgent、systemLanguage
该对象信息具有误导性,一方面数据可以人为伪造;另一方面,浏览器无法报告晚于浏览器发布的新操作系统
尝试访问不同浏览器的特殊属性,如Opera浏览器的opera属性if(window.opera){.....}
alert(MESSAGE):警告弹框,需要点击确定才能继续操作
如果信息内容需要换行,使用换行符\n
confirm(MESSAGE):确认弹框,需要用户点击确定或取消才能继续操作
确认返回true,取消返回false
prompt(MESSAGE, DEFAULT_VALUE):提示弹框,要求用户输入值(默认值为参数DEFAULT_VALUE),点击确定或取消
若点击确定,返回输入值;若点击取消,返回null
var t=setTimeout("JS语句", 毫秒);clearTimeout(t);将document.cookie作为一个字符串去玩就可以
TC图形函数库:#include <graphics.h>
平台:watcom
参考资料:
本文多数例子来自上述材料,自己额外添加注释,方便理解
void far initgraph(int far *gdriver, int far *gmode, char *path);
这是早期的dos编程中使用的内存分段模式
far类型表示代码段采用远跳转
near类型表示代码段采用近跳转
但现在的win都采用平坦内存模式,不存在近跳转和远跳转,所以可以不用考虑
一般自动检测即可
即gdriver = 0
此时gmode的参数将被自动检测,但还是得传递一个变量,可以不赋值
如:
int gdriver = 0, gmode;
initgraph(&gdriver, &gmode, ""); //此时gmode并没有赋值
注意:
函数的形参都是指针,不要直接传递整型数据
通过graphresult()函数返回图形模式初始化结果
与常量grOk进行比较
注意:graphresult()必须在initgraph()之后调用
int gdriver = 0, gmode;
initgraph(&gdriver, &gmode, "");
errorcode = graphresult();
if(errorcode != grOk)
{
printf("Graphics error: %s\n", grapherrormsg(errorcode));
printf("Press any key to halt:");
getchar();
exit(1);
}
屏幕一般分为25或40或50行,80或40列
以左上角为原点(1,1),向右为x正方向,向下为y正方向
屏幕被划分为像素,每个像素为一个点,像素的个数与视频适配器的类型和适配器的工作方式有关
系统默认以左上角为原点(0,0),向右为x正方向,向下为y正方向
注意:文本模式跟图形模式的原点坐标不同
getmaxx()函数返回当前图形模式下的最大x坐标(整型)getmaxy()函数返回当前图形模式下的最大y坐标(整型)
选择一个原点,建立以右为x正方向,以上为y正方向的坐标系(符合我们的习惯)
假设选定新的坐标原点(origin_x, origin_y)
原先坐标系的点(before_x, before_y)与新坐标系上的对应点(later_x, later_y)存在以下关系
before_x = origin_x + later_x
before_y = origin_y - later_y
模式间切换不需要重复关闭、初始化图形模式
int far getgraphmode(voide);
注意:前提是已经成功调用过initgraph()函数
void far restorecrtmode(void);
closegraph();text_mode();textmode(C80);
void far setgraphmode(int mode);
//......省略图形初始化的代码
gmode = getgraphmode(); //获取当前图形模式
restorecrtmode(); //恢复为文本模式
setgraphmode(gmode); //设置(恢复)为之前的图形模式并清屏
void far closegraph(void);
所有的有关图形的程序段必须在initgraph()和closegraph()之间(类型于文件操作)
背景色: setbkcolor(int color);
作图色: setcolor(int color);
可以使用常量或数值表示
9-13为1-5对应的浅色
void far putpixel(int x, int y, int pixelcolor);
获取最大x坐标:int far getmaxx(void);
获取最大y坐标:int far getmaxy(void);
获取当前x坐标:int far getx(void);
获取当前y坐标:int far gety(void);
移动画笔到绝对坐标:void far moveto(int x, int y);
移动画笔到相对坐标:void far moverel(int dx, int dy);
只支持英文输出,且文字大小固定,为8*16点阵
在当前位置输出文本:void far outtext(char far *textstring);
在指定位置输出文本:void far outtextxy(int x, int y, char *textstring);
指定直线起止点:void far line(int x0, int y0, int x1, int x2);
以当前位置为直线起点,指定终点(绝对坐标),并移动画笔:void far lineto(int x, int y);
以当前位置为直线起点,指定终点(相对坐标),并移动画笔:void far linerel(int dx, int dy);
画圆:void far circle(int x, int y, int radius);
画圆弧:void far arc(int x, int y, int stangle, int endangle, int radius);stangle和endangle参数采用角度制(0-360),以x轴正方向为0度,以逆时针为正方向
void far ellipse(int x, int y, int stangle, int endangle, int xradius, int yradius);
void far rectangle(int left, int top, int right, int bottom);
指定左上角的坐标为(left, top),右下角的坐标为(right, bottom)
void far setlinestyle(int linestype, unsigned upattern, int thick);
USERBIT_LINE或4,则该参数取0即可 void far setfillsytle(int pattern, int color);
pattern可以采用常量或数值:
void far floodfill(int x, int y, int bcolor);
(x, y)为所要填充的有界区域的任意点
bcolor不是填充色,而是边框颜色
void far fillellipse(int x, int y, int xradius, int yradius);
void far sector(int x, int y, int stangle, int endangle, int xradius, int yradius);
void far fillpoly(int numpoints, int far *polypoints);
polypoints参数为各个点的坐标,存放规则如下:(假设一个poly数组)
(poly[0], poly[1]) 为第一个顶点
(poly[2], poly[3]) 为第二个顶点
…………以此类推
void load_8bit_bmp(int x, int y, char *path);
#include <graphics.h>
#include <stdio.h>
main()
{
int x, y;
int driver=0, mode=VESA_1024x768x8bit;
initgraph(&driver, &mode, "");
load_8bit_bmp(0, 0, "pic256.bmp");
load_8bit_bmp(200, 200, "hello.bmp");
getchar();
closegraph();
}
通过读取bmp文件的二进制数据输出图片
#include <graphics.h>
#include <stdio.h>
#include <mem.h>
int load_24bit_bmp(int x, int y, char *filename)
{
FILE *fp = NULL;
byte *p = NULL; /* pointer to a line of bmp data */
byte *vp = _vp + (y*_width + x) * (_color_bits/8);
dword width, height, bmp_data_offset, bytes_per_line, offset;
int i;
p = malloc(1024L * 3); /* memory for holding a line of bmp data */
if(p == NULL) /* cannot allocate enough memory for drawing 1 line */
goto display_bmp_error;
fp = fopen(filename, "rb");
if(fp == NULL) /* cannot open bmp file */
goto display_bmp_error;
fread(p, 1, 0x36, fp); /* read BMP head */
if(*(word *)p != 0x4D42) /* check BMP signature */
goto display_bmp_error; /* not a BMP file */
if(*(word *)(p+0x1C) != 24)
goto display_bmp_error; /* not a 24-bit-color BMP file */
width = *(dword *)(p+0x12);
height = *(dword *)(p+0x16);
bmp_data_offset = *(dword *)(p+0x0A);
fseek(fp, bmp_data_offset, SEEK_SET); /* skip BMP head */
bytes_per_line = (width * 3 + 3) / 4 * 4; /* must be multiple of 4 */
for(i=height-1; i>=0; i--) /* draw from bottom to top */
{
fread(p, 1, bytes_per_line, fp); /* read a line of bmp data */
offset = i * 1024 * 3;
memcpy(vp+offset, p, width*3);
}
free(p);
fclose(fp);
return 1;
display_bmp_error:
if(p != NULL)
free(p);
if(fp != NULL)
fclose(fp);
return 0;
}
main()
{
int driver=0, mode=VESA_1024x768x24bit;
initgraph(&driver, &mode, "");
load_24bit_bmp(0, 0, "pic.bmp");
getchar();
closegraph();
}
字库有固定的字体大小
读取字库文件中对应文字的16*16点阵共32字节的信息,若为1则在对应的位置上输出一个点,否则跳过
示例:(读取16*16的字库,并将其放大四倍打印)
#include <graphics.h>
void draw_hz(byte buf[16][2]);
main()
{
int driver=0, mode=VESA_640x480x8bit;
FILE *fp;
byte hz[3]="我", buf[16][2]; //每个汉字占用两个字节
long offset;
int x, y, button;
initgraph(&driver, &mode, "");
fp = fopen("hzk16", "rb"); // 打开16x16点阵字库文件
if(fp == NULL)
{
puts("Cannot open file hzk16.");
exit(0);
}
// 计算"我"字点阵的偏移位置
offset = ((hz[0] - 0xA1) * 94 + (hz[1] - 0xA1)) * 0x20; //呃?这是啥?莫非是固定的计算公式?
fseek(fp, offset, SEEK_SET); // 移动文件指针到该偏移位置
fread(buf, 1, 2*16, fp); // 读取32字节点阵数据
fclose(fp);
draw_hz(buf); // 画"我"字
getchar();
closegraph();
}
void draw_hz(byte buf[16][2])
{
word sixteen_dots;
int x0=_width/2-32, y0=_height/2-32; //打印的起始位置
//居中显示,注意我们把字库的字体放大了四倍,也就是实际上打印出来是64*64的点阵汉字
int x, y; //当前打印的“点”的坐标
int i, j;
x = x0;
y = y0;
for(i=0; i<16; i++) // 16行
{
sixteen_dots = buf[i][0]<<8 | buf[i][1]; // 把两个一字节的word合并为一个两字节的int,共16位,代表1行16个点
for(j=0; j<16; j++) // 16列
{
if(sixteen_dots & 1<<(15-j)) // 判断第(15-j)位是否为1, 为1表示有笔画
//假设j=14,则1<<(15-j)的结果为0000 0000 0000 0010
//假设sixteen_dots为...........0101 0101 0101 0101
//取位“与”即可判断第2位是否为1
{
setfillstyle(SOLID_FILL, RED);
bar(x, y, x+3, y+3); // 画一个4*4的红色方块代替一个前景点
}
else // 第(15-j)位为0,为0表示没笔画
{
setfillstyle(SOLID_FILL, BLACK);
bar(x, y, x+3, y+3); // 画一个4*4的黑色方块代替一个背景点
}
x += 4; //把“画笔”移动到当前行的下一个4*4的“点”的位置
}
//把“画笔”移动到下一行第一个4*4的“点”的位置
x = x0;
y += 4;
}
}
缺陷:当字体放大时,会出现明显的锯齿形
有两种方式——
1、将多行字符串转换为多幅图片再输出,速度较快
2、逐行输出字符串
相关类型——
typedef struct _PIC // 照片结构类型
{
struct picture *img; // 照片的图像
struct picture *mask; // 照片的掩码
int width, height; // 照片的宽度及高度
} PIC;
相关函数——
字符串转换为图片PIC * get_ttf_text_pic(char text[], char fontname[], int fontsize);
text为要转换的字符串
fontname为使用的曲线字库
fontsize为字体大小
返回指向图片(PIC)的指针
绘制图片void draw_picture(int x, int y, PIC *p);
p为指向所要绘制的图片的指针
销毁图片,释放资源void destroy_picture(PIC *p);
只有一个参数(指针),为指向所要销毁的图片的指针
直接打印字符串dword out_ttf_text_xy(int x0, int y0, char text[], char fontname[], int fontsize);
返回32位整型,高16位记录图片宽度,低16位记录图片高度
示例:
#include <stdio.h>
#include <graphics.h>
main()
{
int driver=0, mode=VESA_1024x768x24bit;
short int x=0, y=100;
int i;
PIC *p[4];
initgraph(&driver, &mode, "");
/* TTF字体输出演示1: 先把多行字符串转化成多幅照片, 再输出, 速度较快 */
setcolor(0xFF0000); // 红色
p[0] = get_ttf_text_pic("A QUICK BROWN FOX JUMPS", "courier.ttf", 40);
// 把字符串转化成照片, 其中"courier.ttf"是TTF字库名, 40是字体大小
// p[0]用来接收函数返回的照片指针
setcolor(0xFFFF00); // 黄色
p[1] = get_ttf_text_pic("a quick brown fox jumps", "courier.ttf", 36);
setcolor(0x00FF00); // 绿色
p[2] = get_ttf_text_pic("0123456789", "courier.ttf", 32);
setcolor(0x0000FF); // 蓝色
p[3] = get_ttf_text_pic("`~!@#$%^&*()-=_+[]{}\\|;:'\",.<>/?", "courier.ttf", 28);
for(i=0; i<4; i++)
{
draw_picture(x, y, p[i]); // 在(x,y)坐标输出照片p[i]
y += p[i]->height; // 计算下一行的y坐标
destroy_picture(p[i]); // 销毁已画照片占用的资源
}
getchar();
/* TTF字体输出演示2: 逐行输出字符串, 速度较慢 */
driver=0;
mode=VESA_1024x768x8bit;
initgraph(&driver, &mode, "");
y = 100;
setcolor(LIGHTRED);
y += out_ttf_text_xy(x, y, "夏天的飞鸟,飞到我窗前唱歌,又飞去了。", "simyahei.ttf", 40);
// 函数的返回值 = (照片宽度<<16) | 照片高度
// 故类型为short int的y实际仅加上照片高度值, 从而得到下行的y坐标
y += out_ttf_text_xy(x, y, "Stray birds of summer come to my window", "courier.ttf", 32);
y += out_ttf_text_xy(x, y, "to sing and fly away.", "courier.ttf", 32);
setcolor(YELLOW);
y += out_ttf_text_xy(x, y, "秋天的黄叶,它们没什么可唱,", "simyahei.ttf", 36);
y += out_ttf_text_xy(x, y, "And yellow leaves of autumn", "courier.ttf", 28);
y += out_ttf_text_xy(x, y, "which have no songs", "courier.ttf", 28);
setcolor(LIGHTGREEN);
y += out_ttf_text_xy(x, y, "只叹息一声,", "simyahei.ttf", 32);
y += out_ttf_text_xy(x, y, "Flutter and fall there", "courier.ttf", 24);
setcolor(LIGHTBLUE);
y += out_ttf_text_xy(x, y, "飞落在那里。", "simyahei.ttf", 28);
y += out_ttf_text_xy(x, y, "with a sigh.", "courier.ttf", 20);
getchar();
closegraph();
}
过于机械麻烦,这里跳过
只支持midi音乐文件和wav波形文件
相关类型——
知道有这两个类型即可,具体成员不必深究
typedef struct midi // MIDI file data structure
{
word format; // 0 or 1
word num_tracks; // 1 - 32
word divisions; // number ticks per quarter note
byte *track[16]; // Track data pointers
word repeat;
struct midi *chain;
void (*chainfunc)(struct midi *);
} MIDI;
typedef struct wave
{
dword id;
dword sample_rate;
dword byte_rate;
byte *data;
dword chunk_size; // size of this chunk in bytes
dword sample_size; // size of entire linked sample
struct wave *next; // points to next link.
struct wave *head; // points to top link.
} WAVE;
相关函数——
int initsound(void); WAVE * load_wave(char *filename);MIDI * load_midi(char *filename); void play_wave(WAVE *p, int repeat);void play_midi(MIDI *p, int repeat);void free_wave(WAVE *p);void free_midi(MIDI *p); void closesound(void); 示例:
#include <graphics.h>
main()
{
MIDI *pmidi;
WAVE *pwave;
initsound(); // 初始化声卡
pmidi = load_midi("bach.mid"); // 载入midi文件, 返回MIDI指针
pwave = load_wave("sheep.wav"); // 载入wav文件, 返回WAVE指针
play_midi(pmidi, -1); // repeat forever 播放midi音乐
play_wave(pwave, 3); // repeat 3 times 播放wav声音
puts("Press a key to continue.\n");
getchar();
free_midi(pmidi); // 释放midi音乐占用的资源
free_wave(pwave); // 释放wav声音占用的资源
closesound(); // 关闭声卡
return 1;
}
详细函数——(包括一些控制函数)
int initsound(void); // 声卡初始化
void closesound(void); // 关闭声卡
WAVE * load_wave(char *filename); // 载入wav文件
void play_wave(WAVE *p, int repeat); // 播放wav, repeat为循环次数, repeat=-1为无限循环
void stop_wave(WAVE *p); // 停止播放wav
void pause_wave(WAVE *p); // 暂停播放wav
void resume_wave(WAVE *p); // 继续播放wav
void free_wave(WAVE *p); // 释放wav占用的资源
MIDI * load_midi(char *filename); // 载入midi文件
void play_midi(MIDI *p, int repeat); // 播放midi, repeat为循环次数, repeat=-1为无限循环
void stop_midi(MIDI *p); // 停止播放midi
void pause_midi(MIDI *p); // 暂停播放midi
void resume_midi(MIDI *p); // 继续播放midi
void free_midi(MIDI *p); // 释放midi占用的资源
bioskey(0)bioskey(1)什么是键盘缓冲区?
CPU能在运行程序时处理外部中断(interrupt)。当用户按下某个键时,键盘会向CPU发出一个中断请求,此时CPU会暂停正在运行的程序而转去处理键盘中断,处理的结果是把当前按住的键读走并存放到键盘缓冲区中。键盘缓冲区是一个队列(queue),相当于一个数组。
int x, y, b;
union REGS r;
r.w.ax = 0x0003; /*调用0003号功能*/
int86(0x33, &r, &r);
x = r.w.cx; /* 当前鼠标的x坐标 */
y = r.w.dx; /* 当前鼠标的y坐标 */
b = r.w.bx; /* 当前鼠标的按键状态 */
其他常见功能:
详见中断大全
通过直接给坐标对应的内存赋值画图
一些程序可能会出现byte, word, dword类型
其实这都是自定义类型byte对应charword对应shortdword对应int
_vp: 指向坐标(0,0)的指针_width: 屏幕宽度_height: 屏幕高度_color_bits: 每个像素占用内存的位(bit)数_visual_page: 当前显示画面(前景)对应的页号_active_page: 当前输出画面对应的页号_back_page: 后台画面(背景)对应的页号_page_gap: 后台画面与显示画面的距离_mode_index: 当前视频模式的编号_mode: 当前视频模式的内部编号_draw_color: 前景色_back_color: 背景色_fill_color: 填充前景色_fill_mask_index: 填充掩码_x: 当前x坐标_y: 当前y坐标指向(x,y)的指针p,指向char类型数据公式:p = _vp + ( y * _width + x ) * ( _color_bits / 8 )
解释:((x, y)的指针) = (原点指针) + (跳过的元素总数) * (每个元素占用的字节)
每个元素占用两个字节——
每个指针指向一个一字节(8位)的数据
示例(输出一个蓝底红字的A):
char *p = _vp;
*p = 'A';
*(p+1) = ( BLUE << 4 ) + RED; //或*(p+1) = 0x14;
watcom平台提供的VESA图形库中相关常量:
包含8bit,24bit, 32bit三种颜色模式
每个点占用显卡一个字节,每个点有2^8(256)种颜色,前十六种(0~15)颜色定义如下:
enum COLORS
{
BLACK, /* dark colors */
BLUE,
GREEN,
CYAN,
RED,
MAGENTA,
BROWN,
LIGHTGRAY,
DARKGRAY, /* light colors */
LIGHTBLUE,
LIGHTGREEN,
LIGHTCYAN,
LIGHTRED,
LIGHTMAGENTA,
YELLOW,
WHITE
};
每个点占用显卡三个字节,分别代表RGB的蓝色(B),绿色(G),红色(R),(没错,就是逆序的),每个点有2^24种颜色。
示例:
char *p;
p = _vp;
*p = 0x56; //Blue
*(p+1) = 0x34; //Green
*(p+2) = 0x12; //Red
每个点占用显卡四个字节,前三个字节表示RGB(同24bit),第四个字节通常为0x00
显示页面存在两个层次,前景和背景_active_page为当前输出的页面_visual_page为当前显示的页面,非显示页面将被隐藏_back_page为当前的背景页setviualpage()函数能够设置显示页面setactivepage()函数能够设置输出页面
示例:
setvivualpage(_back_page); //表示将背景页设置为当前显示页面
stactivepage(_back_page); //表示将背景页设置为当前输出页面
参考资料:requests官方文档
嗯……据说requests是基于urllib3的第三方库
简单的使用如下:
返回一个response对象
第一个参数为页面的url,可以加入关键词参数cookies
也是返回一个response对象
第一个参数为页面的额url,可以加入关键词参数headers和data
headers即为Requests Headers的内容,参数形式是一个字典
data即为form data的内容,参数形式也是一个字典
参考资料:beautifulsoup官方文档
一般情况下可以直接当作它的子对象tag对象来使用
其中包含以下子对象
对象的名称与html和xml的标签名都相同
<head><title>aaa</title></head>soup.children将会获取<title>aaa</title>整个直接子节点soup.descendants则会获取aaa这样的子孙节点 即尖括号<>之外的内容
find_all方法
查找标签
直接访问tag对象只能得到第一个匹配结果,如果需要得到所有结果需要借助find_all函数
函数返回一个包含所有该标签的内容的列表
soup.find('a', id='link3') True将表示匹配任何值find方法
用法与find_all类似
chardet或cchardet可以大大提高自动检测的准确率这个比较简单,从源码中找到所需要的信息,观察它的规则,用正则表达式表达出来并且借助re模块的函数进行匹配提取即可
比如:我要爬下十大的标题——
查看源码:
<a href="dispbbs.asp?boardid=736&id=4508354" target="_blank"><font color=#000066>[CIE创道人生大讲堂]世界那么大,出去创业吧——为你讲述众筹之王的创业之道(抢楼有大礼哦~)</font></a>
<a href="dispbbs.asp?boardid=114&id=4508053" target="_blank"><font color=#000066>真是哔狗了,刚加的妹子被我吓跑了</font></a>
<a href="dispbbs.asp?boardid=100&id=4508066" target="_blank"><font color=#000066>[微创业联盟]创业,就问你约不约!——抢楼有精美礼品相赠哦!</font></a>
......(这里仅列出三条)
可以找到其中的规律,并且用以下正则表达式表示:
<a href="dispbbs\.asp\?boardid=[0-9]+&id=[0-9]+" target="_blank"><font color=#000066>(.+?)</font></a>
[0-9]+进行匹配(.+?)进行匹配然后用re.findall函数把匹配项都找出来就可以了
接着我们把内容写入文件,比如把包含所有匹配项的titles写到/home/zk/TopTen文件中去
import codecs, os
f = codecs.open('/home/zk/TopTen', 'w', 'utf-8')
for i, title in zip( range(1,11), titles ):
f.write( str(i) + title + os.linesep )
f.close()
因为写入的内容包含中文,所以我们需要使用codecs模块的open函数打开文件,指定编码为utf-8
借助chrome的开发者工具,可以捕捉到网页的相关信息
登录后,我们只要找到POST了包含用户名信息的页面,就可以找到处理登录的页面
cc98是post到sign.asp中去
查看这个页面的post信息,主要关注以下的信息
General
Request URL:http://www.cc98.org/sign.asp
#
Request Headers
Accept:text/plain, /; q=0.01
Accept-Encoding:gzip, deflate
Accept-Language:en-US,en;q=0.8
Connection:keep-alive
Content-Length:60
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:ASPSESSIONIDQSCRDADB=NMLCLJEDIAGPHCHGOKDBHPGN; upNum=0; aspsky=username=zkkzkk&usercookies=3&userid=509527&useranony=&userhidden=2&password=6cc9bed70c3c80e1; BoardList=BoardID=Show; owaenabled=True; autoplay=True
Host:www.cc98.org
Origin:http://www.cc98.org
Referer:http://www.cc98.org/
User-Agent:Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36
X-Requested-With:XMLHttpRequest#
Form Data
a:i
u:zkkzkk
p:*
userhidden:2
Host不是自己指定和设置的,http请求会自动处理Content-Type、User-Agent、Accept-Encoding必须有,值照抄即可 a和userhidden不知道是什么意思,先照搬u显然是用户名p则是密码,这里安全起见,我把他用星号代替了,这里其实是一个用hashlib.md5加密了的密码 requests.post函数即可模仿post#headers主要照搬Requests Headers的信息,删去Host和Cookie即可
headers = {
'Accept':'text/plain, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'en-US,en;q=0.8',
'Connection':'keep-alive',
'Content-Length':'60',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Origin':'http://www.cc98.org',
'Referer':'http://www.cc98.org/',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
#payload为一些表单信息
payload = {
'a' : 'i',
'u' : 'zkkzkk',
'p' : '***********',
'userhidden' : '2'
}
r = requests.post('http://www.cc98.org/sign.asp', data=payload, headers=headers)
函数返回一个包含登陆信息cookies的对象r
接下来我们只要用这个cookies去访问cc98上的页面即可
rr = requests.get('http://www.cc98.org', cookies=r.cookies)
先上源码——
# coding: utf-8
import requests,sys,bs4,re,urllib,os,codecs
#设置编码为utf8,不然后边对中文进行url编码的时候会出现奇怪的错误
reload(sys)
sys.setdefaultencoding('utf8')
#登录URL
URL = 'http://10.71.45.100/cstcx/web/login/check.asp?tn=xjc&Rnd.7055475=.533424'
#HEADERS
#这里只去掉了Request Headers中的Host和Cookie,其他照搬
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'en-US,en;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Content-Length':'32',
'Content-Type':'application/x-www-form-urlencoded',
'Origin':'http://10.71.45.100',
'Referer':'http://10.71.45.100/cstcx/web/index.asp?tid=27&tt=xjc&tn=%D0%EC%BE%B5%B4%BA&Rnd.5751838=.1000522',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'
}
#FORM DATA
payload = {
'txtUser':'3140100805',
'txtPwd':'123456'
}
#模拟登录
check = requests.post(URL, data=payload, headers=headers)
#“参考资料”URL
rsrcURL = 'http://10.71.45.100/cstcx/web/courceinfo/resource.asp?coid=18&flag=0&coname=C%D7%A8%CC%E215&clsid=25&clsname=C%D7%A8%CC%E215&techid=27&loc=%BF%CE%B3%CC%D0%C5%CF%A2%3E%3E%3E%B2%CE%BF%BC%D7%CA%C1%CF'
#“讲稿”URL
docuURL = 'http://10.71.45.100/cstcx/web/courceinfo/jianggao.asp?coid=18&loc=%BF%CE%B3%CC%D0%C5%CF%A2%3E%3E%3E%BD%B2%B8%E5'
#“参考资料”本地存放目录
rsrcDIR = '/home/zk/C大程资料/Resources/'
#“讲稿”本地存放目录
docuDIR = '/home/zk/C大程资料/Documents/'
def GetHref(URL):
'''
利用模拟登录获得的cookies访问“参考资料”或“讲稿”的页面
获取所需资源的名称和url并返回(字典)
'''
resources = requests.get(URL, cookies=check.cookies)
resources.encoding = 'gb2312' #requests识别出来的是iso,需要手动修改
rsrc_soup = bs4.BeautifulSoup(resources.text) #用BeautifulSoup处理页面内容
rsrc_a = rsrc_soup.find_all('a') #找出页面内容中的a标签
rsrc = {} #初始化一个字典,用于储存name-href键值对
for a in rsrc_a: #逐个处理每个a标签
href = re.findall('href="(.+?)"', str(a))[0] #用正则表达式筛选出文件的url
href = href.replace('../../', 'http://10.71.45.100/cstcx/') #由于页面上写的是相对路径,我们需要将其恢复为绝对路径,以便后边的正常访问
name = href.split('/')[-1] #截取文件名
rsrc[name] = href #存入字典
return rsrc
def Download(rsrc, DIR):
'''
依据本地文件名判断文件是否已经下载过
如果是新文件则下载到本地、打印下载信息
注释掉的代码为原先采用文件记录的形式判断是否重复
'''
#lst = open(DIR + 'list','r')
#lst_name = lst.readlines()
#lst.close()
#lst = codecs.open(DIR + 'list', 'a','utf8')
lst_name = os.listdir(DIR) #获取本地目录的文件名
for name,url in rsrc.items(): #逐个处理所获取的name-href键值对
if name not in lst_name: #如果这个文件不在本地?
#lst.write(name + os.linesep)
urllib.urlretrieve(url, DIR + name) #下载该文件
print 'New file: ' + DIR + name #打印信息
#lst.close()
def main():
rsrc = GetHref(rsrcURL)
Download(rsrc, rsrcDIR)
docu = GetHref(docuURL)
Download(docu, docuDIR)
print 'Finished~'
if __name__ == '__main__':
main()
信息的抓取和登录模拟就跟玩CC98差不多
在这个玩这个练习的时候呢,主要遇到的是页面的编码问题
ISO8859-1,这是一个英文的编码charset=gb2312gb2312 python编码问题
原先的默认编码是啥我倒是不知道
但是我把取出来的带中文的页面内容作为url去下载文件时会出错,说是不存在页面
后来百度了一下,在程序最前端加入以下代码修改python默认编码即可——
import sys
reload(sys)
sys.setdefaultencoding('utf8')
另外一个问题是如何下载文件,有以下三种方法:
参考资料:python下载文件的三种方法
urllib.urlretrieve直接下载
第一个参数为url,第二个参数为保存的本地路径
如这次的代码
urlli.urlretrieve(url, DIR + name)
urllib2.urlopen获取文件内容,以二进制的形式写入本地文件
url = '.....'
f = urllib2.urlopen(url)
data = f.read()
with open('demo2.zip', 'wb') as code:
code.write(data)
requests.get获取文件内容,以二进制的形式写入本地文件
url = '....'
r = requests.get(url)
with open('demo3.zip', 'wb') as code:
code.write(r.content)
显然urllib模块的方法最简单
